PageIndex 官网两篇文章:
- PageIndex: Next-Generation Vectorless, Reasoning-based RAG 2025.9.19
- From Claude Code to Agentic RAG 2025.9.1
腾讯云开发者:RAG已死?不,是Grep回归了! 2026.4.30
根据以上内容,我总结了目前文档/代码检索的最新范式与它们的 tradeoffs
一、The Limitations of Vector-based RAG 向量检索的局限#
Classic RAG Pipeline 经典 RAG 管道:
split content into chunks → embed → store in a vector DB → semantic search → (blend with keyword search) → (rerank) → stuff the context → answer
Search for what 检索的目的:找到与答案最相关的文本内容作为有效的知识。
Vector-based RAG‘s Assumption 向量检索的假设:与查询语义最相似的文本就是最相关的,能作为有效知识。
这个假设反映了向量检索严重依赖静态语义相似度,这伴随着如下问题:
-
为什么要把文本与“查询“作比较,查询通常表达的是意图,而非知识内容。
——「查询空间与知识空间不匹配 Query and knowledge space mismatch」
-
为什么判断相关性的标准是“语义相似性”,在特定领域文档(财务文件、法律文件和技术手册)中许多段落的语义几乎相同,但相关性却大相径庭。
——「语义相似性并不等同于相关性 Semantic similarity is not equivalent to relevance」
-
语义相似性的判断标准还导致 「文档内引用难以处理 Hard to deal with in-document reference」
文档中经常包含诸如“参见附录 G”或“参见表 5.3”之类的引用。由于这些引用与被引用的内容语义相似度不高,传统的 RAG 方法会遗漏它们,除非进行额外的预处理(例如构建知识图谱)。
同时向量检索范式本身还伴随着以下局限:
-
「硬分块破坏语义和上下文的完整性 Hard chunking breaks semantic and contextual integrity」
-
「无法利用历史对话 Cannot integrate chat history」
每个查询都会被独立处理。检索器不知道之前问过什么或回答过什么。
其他问题:
- 索引成本高
- 没有标准的benchmark,相关性调试困难
二、Claude Code 的选择 — Agentic Search#
CC 完全放弃了向量数据库和索引,
-
依靠 LLM 自主规划驱动,
-
依赖传统的
grep/glob等命令行工具,Glob通过通配符模式匹配文件路径来快速定位文件Grep借助ripgrep在文件内容中进行高速的正则表达式文本匹配来查找函数定义等
-
执行“搜索-分析-再搜索”的动态循环。
-
唯一的索引:文件路径模糊索引
它摒弃了对代码内容的预建索引,出于交互中文件导航需求,仅利用
nucleo模糊匹配算法对“文件路径”建立轻量级索引。
| 对比维度 | Agentic Search (Claude Code) | RAG (如 Cursor/Windsurf) |
|---|---|---|
| 核心原理 | 传统 grep/glob 命令进行精确匹配 | 代码向量化为 Embedding 后进行语义相似度搜索 |
| 索引机制 | 无预建索引,轻量级“文件路径”模糊索引 | 预建索引,需维护 AST 语义切片、向量数据库 |
| 时效性 | 实时性强,代码库任何变更即时反映 | 存在滞后,需增量同步或重建索引,成本高 |
| 隐私安全 | 代码不离开本地环境,无泄露风险 | 索引可能被泄露,存在安全隐患 |
| Token 消耗 | 全文本搜索可能消耗 大量 Token | 语义检索更精准,可有效 减少约 40% Token |
| Token 成本 | 一次性使用,无缓存成本 | 索引存储和计算存在隐性成本 |
Tree-sitter 是一个解析器生成工具和增量解析库,它为代码编辑器、代码分析工具等提供快速、容错、实时的代码解析能力,而 AST 是它完成解析后生成的核心产物,只不过这个产物更精确地说是具体语法树(CST)。 AST 的全称是 Abstract Syntax Tree(抽象语法树)。它本身不是索引,但可以作为构建“代码语义索引”的核心依据。
Tree-sitter 自带一套模式匹配查询语言,你可以把它想象成“专门为语法树设计的正则表达式”。它能让你轻松地在语法树中查找特定的代码结构(例如“找出所有将箭头函数赋值给对象属性的操作”),在编写代码重构或静态分析工具时极为高效,省去了繁琐的树遍历代码。
它是下一代编辑器/IDE的核心:Neovim、Helix、Zed 等新一代编辑器,均已内置 Tree-sitter 来实现精确的语法高亮和代码选择。
ast-grep:一个命令行工具,允许你使用类似高级正则的语法,对整个代码库进行结构化搜索、代码检查(lint)和批量重构。
Pros 优势#
Claude Code 对 Agentic Search 的选择,反映了在代码库这类高频变化场景下,对绝对实时性、准确性和安全性的极致追求,其代价则是更高的 Token 消耗。
零启动成本#
用户安装 Claude Code 后可以立即使用,不需要等待索引构建。对于大型仓库,索引构建可能需要数分钟甚至更长时间。
与文件系统实时同步#
实时搜索的结果永远是最新的,不存在索引过期的问题。在频繁修改代码的开发场景中,索引的新鲜度是一个持续的工程挑战。
模型能力的替代#
Claude 模型本身具备强大的代码理解能力。给定搜索结果和文件内容,模型可以理解代码结构、追踪调用链、推断类型关系。这些能力在传统工具中需要通过索引来实现,但在 LLM 时代可以由模型直接完成。
ripgrep 足够快#
ripgrep 在大型仓库上的搜索速度通常在毫秒级别。对于 AI Agent 的使用场景(每次搜索之间有模型推理的延迟),ripgrep 的速度绰绰有余。
ripgrep 的五层过滤
ripgrep 不是对每个文件都做正则匹配。它在真正搜索内容之前,有多层过滤逐步缩小范围:
层级1: 目录级剪枝(.gitignore) — 跳过整棵目录子树,连目录内容都不读取层级2: 路径范围限制(path 参数) — 限定目录遍历的起点层级3: 文件类型过滤(glob 参数) — 遍历目录但跳过不匹配文件层级4: 二进制文件检测 — 读文件头几个字节,发现是二进制就跳过层级5: 内容搜索(正则匹配) — 最后才对通过所有过滤的文件做匹配LSP 作为补充#
对于需要语义理解的场景(跳转定义、查找引用、调用层次),Claude Code 借助语言服务器的索引能力,而非自建索引。
实现#
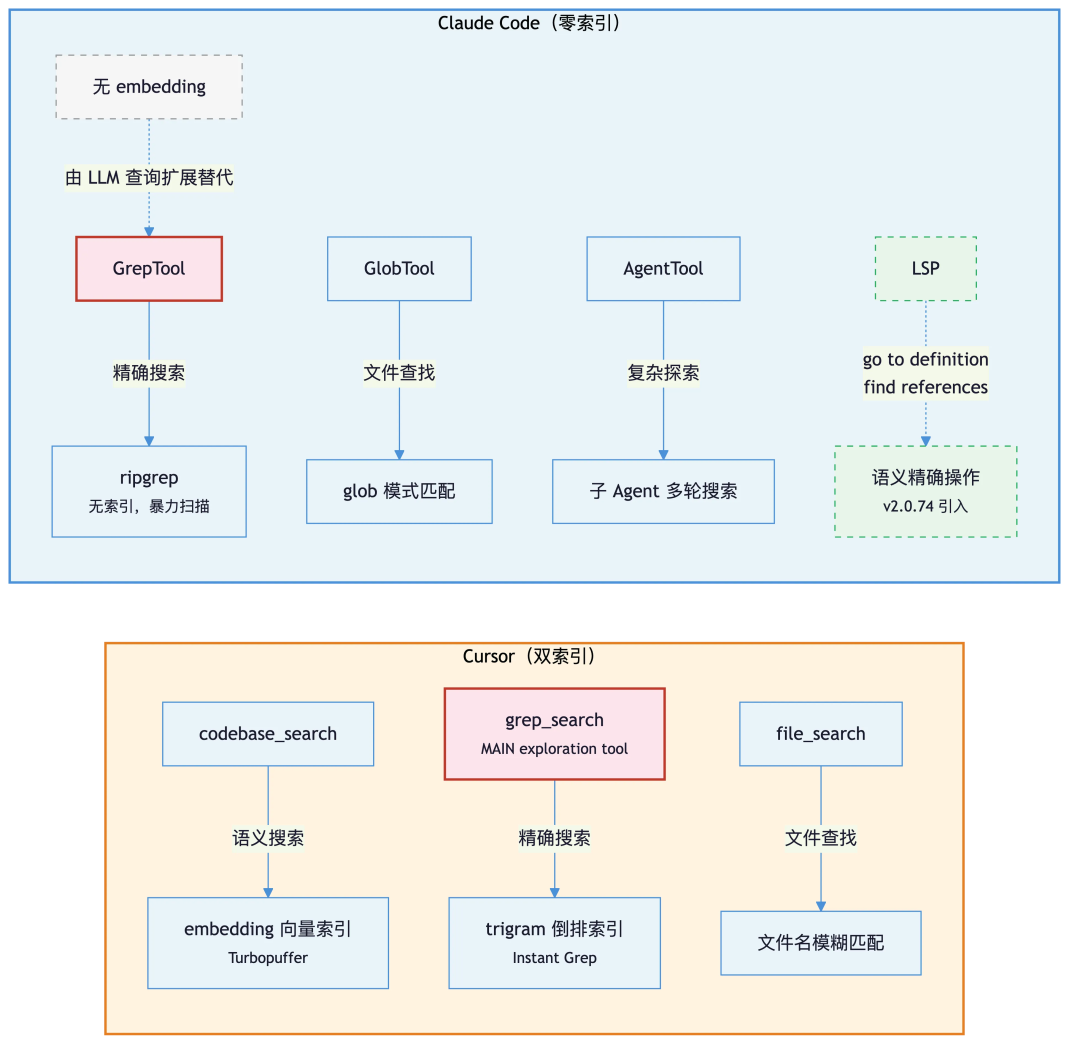
代码内容搜索#
Claude Code 的代码内容搜索没有任何预索引,每次搜索都是实时调用 ripgrep。
| 工具 | 底层实现 | 作用 |
|---|---|---|
| GrepTool | ripgrep (rg) | 正则搜索文件内容 |
| GlobTool | glob 模式匹配 | 按文件名/路径模式查找文件 |
| AgentTool | 独立 LLM 对话 | 启动子 agent 做多步探索 |
子 agent 有多种类型,与搜索最相关的是 Explore 类型:它只配备搜索和读取工具(Grep、Glob、Read),不能编辑文件、不能执行命令、不能嵌套启动新的 Agent,是一个纯只读的搜索专家。
子 agent 的核心价值是 context 隔离。它从零开始构建自己的对话历史,不继承主对话的消息,这意味着它搜索过程中产生的大量 grep 结果、代码片段都留在自己的 context 里,主对话只收到一段总结性的文本结论。对于需要大范围搜索的任务,如果在主对话里直接搜索,几轮 grep/read 下来 context 可能就被中间结果塞满了。因此交给子 agent 处理后,主对话的 context 只增加一条结论消息。
GrepTool#
GrepTool 是代码内容搜索的主要工具,本质上是 ripgrep 的封装:
export const GrepTool = buildTool({ name: 'Grep', searchHint: 'search file contents with regex (ripgrep)', isConcurrencySafe() { return true }, // 只读,可并行 isReadOnly() { return true },
async call({ pattern, path, glob, type, output_mode, ... }) { const args = ['--hidden'] // 排除版本控制目录 for (const dir of ['.git', '.svn', '.hg', '.bzr', '.jj', '.sl']) { args.push('--glob', `!${dir}`) } // 限制行长度,防止 base64/minified 内容污染输出 args.push('--max-columns', '500')
const results = await ripGrep(args, absolutePath, abortController.signal) // ... }})先用 Grep/Glob 找到相关文件,再用 Read 读具体内容。但 Grep 搜到文件后,**是不是每次都要接一个 Read 才能用?**不一定。关键在于 GrepTool 有三种输出模式,返回的信息量完全不同:
- files_with_matches 模式(默认):只返回匹配的文件路径列表,不返回任何代码内容。比如搜 “class.*Transport” 会返回 cli/transports/WebSocketTransport.ts、cli/transports/SSETransport.ts 这样的路径。LLM 拿到的只有文件名,**所以这种模式下通常需要接 Read 才能看到具体代码。**这也是为什么默认模式设计成只返回文件名,即故意控制信息量,避免一次 Grep 就把大量代码涌入 context window,让 LLM 自己判断哪些文件值得深入读取。另外还有一个保护机制:head_limit 默认 250,即使搜到 10,000 条匹配也只返回前 250 条,防止搜索结果淹没 context。
- content 模式:返回匹配行及其上下文代码。比如 Grep({pattern: “TOOL_VERBS”, output_mode: “content”, “-C”: 5}) 会直接返回匹配行前后各 5 行的代码片段。对于很多场景,例如确认一个常量的值、看一个函数签名、检查某个 import 是否存在,这些片段就够了,不需要再 Read 整个文件。
- count 模式:只返回每个文件的匹配数量,用于快速评估搜索词在项目中的分布密度,不返回具体内容。
所以实际的工具组合方式是灵活的:Grep(默认模式)→ Read 是最常见的路径,但 Grep(content 模式)可以独立使用,LLM 也可以直接调 Read(如果已经知道文件路径),或者一次同时发起多个 Grep 并行搜索。这种灵活性是有意为之。其思想是用软引导代替硬约束:system prompt 建议 LLM 先 Grep 定位再 Read 深入,GrepTool 的默认输出模式也自然引导这个流程,但不在代码里堵死其他路径,让 LLM 根据具体情况做判断。
GlobTool#
GlobTool 用于文件模式匹配(如 **/*.tsx),同样基于 ripgrep 的 —files 模式,没有预索引。
系统提示中的搜索策略引导#
Claude Code 通过系统提示引导模型使用正确的搜索策略,而非依赖预建索引:
ALWAYS use Grep for search tasks. NEVER invoke `grep` or `rg` as a Bash command.The Grep tool has been optimized for correct permissions and access.模型被训练为先用 GrepTool 进行宽泛搜索,再用 FileReadTool 读取具体文件。这种”搜索 → 阅读 → 理解”的模式替代了传统的”索引 → 查询”模式。
LSP 集成:借助语言服务器的索引能力#
src/tools/LSPTool/ 是 Claude Code 最接近”语义索引”的部分——但索引工作由外部语言服务器完成,Claude Code 只是客户端。
ToolSearch:工具能力的关键词索引#
ToolSearchTool 实现了一种特殊的”索引”——不是代码索引,而是工具能力索引。
Claude Code 有 40+ 个工具,为了控制初始 prompt 的 token 消耗,非核心工具被标记为 shouldDefer,不在初始 prompt 中发送完整 schema。模型需要通过 ToolSearch 按关键词发现这些工具:
async function searchToolsWithKeywords(query, deferredTools, tools) { for (const tool of deferredTools) { const description = await getToolDescriptionMemoized(tool.name, tools) const hintNormalized = tool.searchHint?.toLowerCase() ?? ''
let score = 0 // 工具名匹配 if (pattern.test(nameParts.full)) score += 10 // searchHint 匹配(策划的能力短语,信号强于 prompt) if (hintNormalized && pattern.test(hintNormalized)) score += 4 // 描述匹配 if (pattern.test(descNormalized)) score += 2 }}每个工具的 searchHint 是一个 3-10 词的能力短语(如 BashTool 的 ‘execute shell commands’、GrepTool 的 ‘search file contents with regex (ripgrep)’),用于关键词匹配。
实战:追踪搜索工具的执行记录#
回到开篇的例子。当然这个问题是我刻意挑的,因为答案分散在多个文件中,需要多轮搜索才能拼出全貌,目的是展示多轮搜索的完整过程。我把这个问题抛给了 Claude Code,以下是真实的搜索过程。
第 1 轮:广撒网。 LLM 把问题中的 GrepTool 和 追踪 翻译成 grep 关键词,用默认的 files_with_matches 模式扫一遍:
Grep({pattern: "GrepTool|tool.*track|tool.*activity", glob: "*.ts"})→ 返回 4 个文件:structuredIO.ts, sessionRunner.ts, bridgeUI.ts, bridgeStatusUtil.ts4 个文件,其中 3 个在 bridge/ 目录下,1 个在 cli/ 下。问题问的是 bridge 系统,LLM 关注 bridge/ 下的文件。sessionRunner.ts(session + runner = 会话执行器)最可能包含工具执行追踪逻辑。

第 2 轮:看上下文。Grep 切换到 content 模式,看 GrepTool 在 sessionRunner.ts 中的上下文:
Grep({pattern: "GrepTool|tool.*activity", path: "bridge/sessionRunner.ts", output_mode: "content", "-C": 5})返回的代码片段中能看到一张映射表的尾部,显示 GrepTool: ‘Searching’、BashTool: ‘Running’,但上文被截断了。LLM 判断需要 Read 整段代码才能看全。

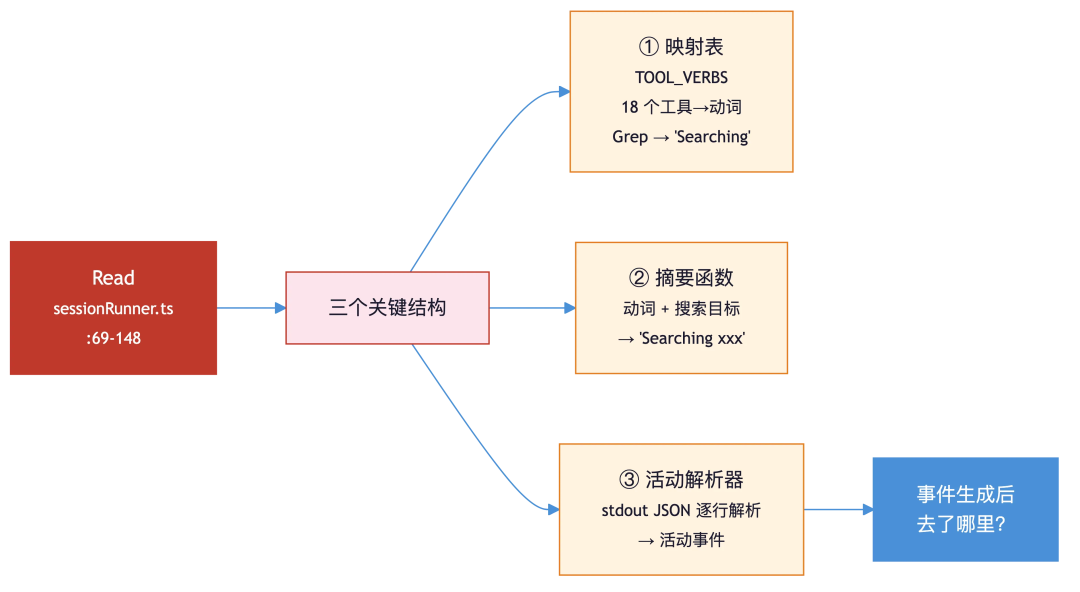
第 3 轮:调用Read。 使用 Read 打开 sessionRunner.ts 的完整上下文,一次看到了三个关键结构:
- 第一个是工具名→动词映射表(TOOL_VERBS,共 18 个条目,这里列出与搜索相关的部分)。每个搜索工具(Grep、Glob)在这里都被映射成 Searching。注意有两套命名,比如内部名 Grep 和外部 SDK 名 GrepTool。这表明工具名是硬编码在映射表里的,不是动态注册的。
Grep: 'Searching', GrepTool: 'Searching',Glob: 'Searching', GlobTool: 'Searching',Read: 'Reading', FileReadTool: 'Reading',Edit: 'Editing', FileEditTool: 'Editing',Bash: 'Running', BashTool: 'Running',// 还有 Write, MultiEdit, WebFetch, WebSearch, Task, NotebookEditTool, LSP 等- 第二个是摘要生成函数,它把动词和搜索目标拼接在一起:动词来自上面的映射表,目标则从工具调用的输入中提取(优先取 file_path,其次 pattern、command、url 等)。所以一次 GrepTool({pattern: “reconnect|backoff”}) 调用的摘要就是 Searching reconnect|backoff。
- 第三个是活动解析器:它从 session 的 stdout 中逐行解析 JSON,当发现工具调用事件时,调用上面的摘要函数生成摘要,打包成一条活动事件。
到这里已经知道了怎么追踪和怎么记录,但活动事件生成之后去了哪里?
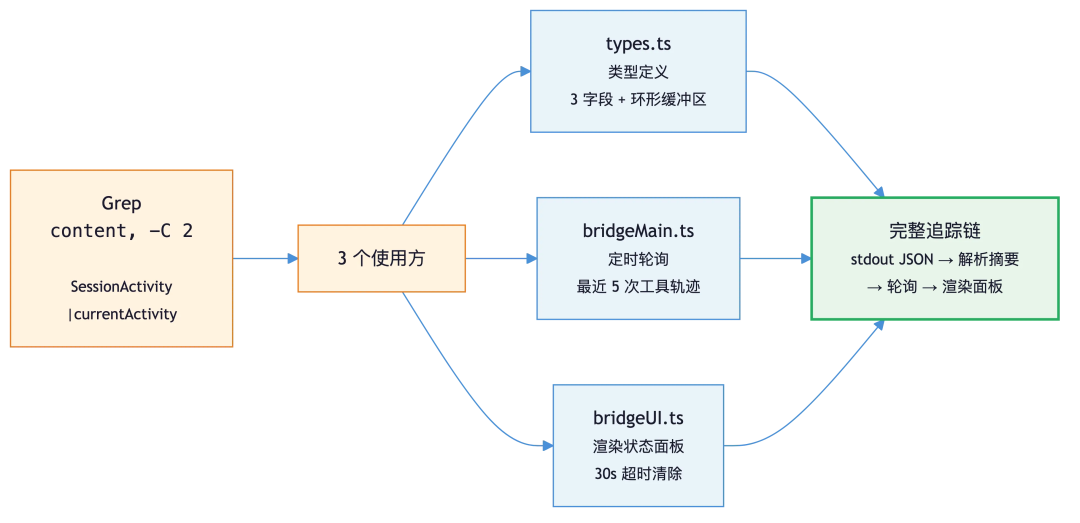
第 4 轮:追踪使用方。 Grep 搜 SessionActivity 被谁引用,一次追出整条链:
Grep({pattern: "SessionActivity|currentActivity", path: "bridge/", output_mode: "content", "-C": 2})三个文件同时浮出水面:
- bridge/types.ts :活动事件的类型定义,只有 3 个字段(类型、摘要、时间戳)。每个 session 维护一个环形缓冲区和一个当前活动指针。
- bridge/bridgeMain.ts :一个定时器周期性轮询每个 session 的当前活动,并维护最近 5 次工具调用的轨迹,例如 Searching → Reading → Searching → Editing 这样的历史。
- bridge/bridgeUI.ts :收到工具启动事件后,缓存摘要文字并渲染到 bridge 的状态面板。
这样就拼出了完整的追踪链:session 进程输出工具调用的 JSON → 活动解析器提取并生成摘要 → bridge 主进程定时轮询获取最新活动 → UI 模块渲染到状态面板。
三、Agentic Retrieval is Emerging 智能体检索#
Claude Code 的成功案例展现了一种新的 Agentic Retrieval 智能体检索范式,通用于本地代码库/文档库/网站:
- No/Light pre-indexing 代码库场景不建立和维护预索引,文档/网站场景轻量预索引,只给 llm 一个紧凑的空间目录(例如一个精心整理的 llms.txt,包含文件的位置、url)
- Only basic retrieval tools 仅给 LLM 一些基本检索工具(grep、glob)
- Let the model decide 让模型根据自身的思考和推理来决定接下来要打开什么
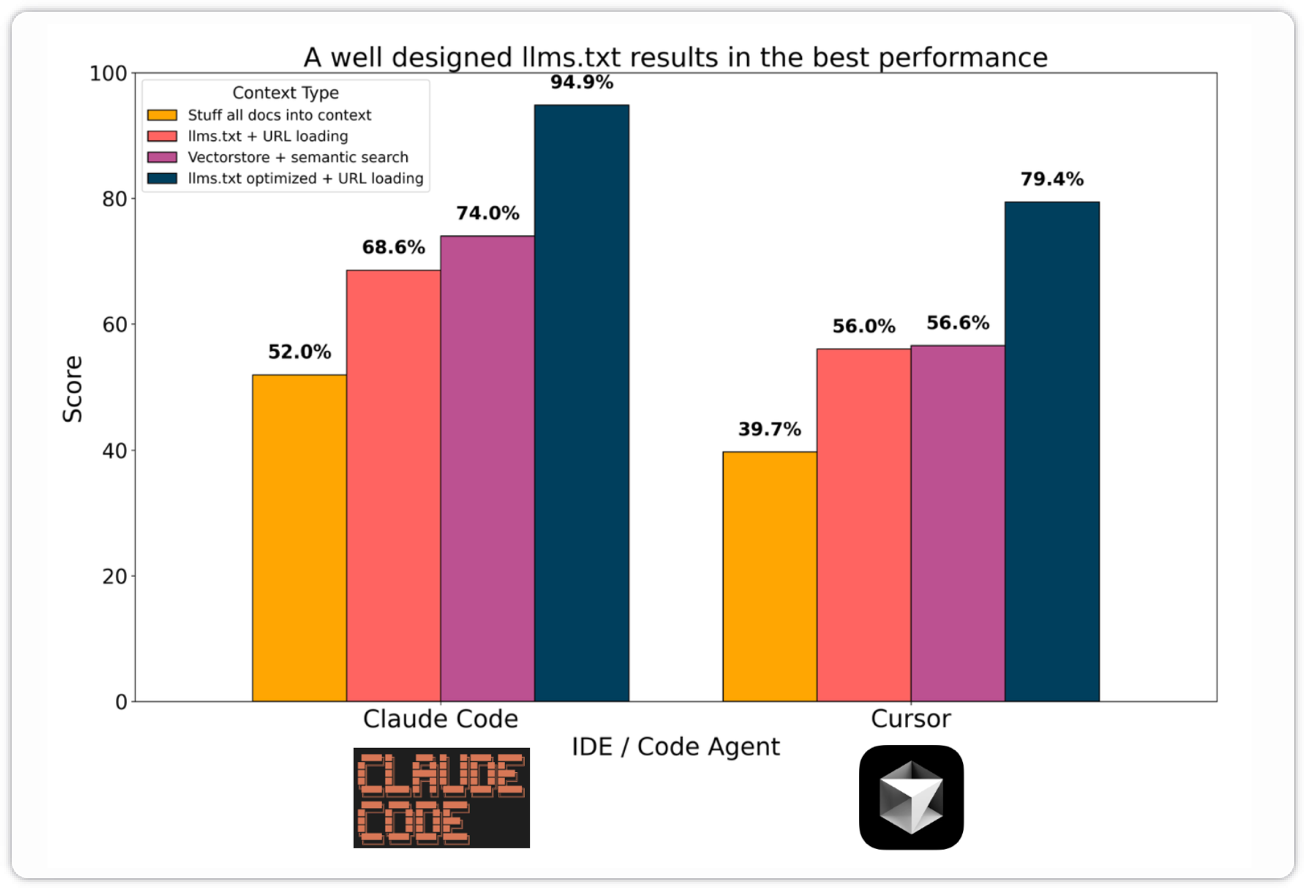
其他依据:这篇 blog Vibe code benchmark 对检索方法进行了基准比较。在对开发者文档的实际测试中,发现精心编写的 llms.txt 文件(包含 URL 和简洁的描述)加上简单的工具调用(例如 grep),在各种编码任务中都优于向量数据库管道。
【llms.txt标准】 Answer.AI创始人Jeremy Howard提出了一个看似简单却意义深远的提案:在网站根目录放一个叫llms.txt的Markdown文件,专门给AI大语言模型看。
传统的sitemap.xml告诉搜索引擎”我有哪些页面”,robots.txt告诉爬虫”哪些能抓哪些不能抓”。但这两个文件都没有回答一个关键问题:如果AI只能看你网站的一小部分,应该看哪些?
llms.txt就是来回答这个问题的。
robots.txt负责访问控制——哪些爬虫可以来,哪些页面不许抓。它是搜索引擎爬虫和AI爬虫都要遵守的基本规则。
sitemap.xml负责完整索引——告诉搜索引擎你网站上所有公开页面的URL和更新频率,是传统SEO的基础设施。
llms.txt负责内容策划——从你的全部页面中精选出最值得AI理解的核心内容,是针对AI搜索场景的增量优化。
llms.txt和llms-full.txt的区别
llms.txt是轻量级的导航文件,只包含网站的结构概览和关键页面的链接列表,类似于一份带注释的目录。AI可以快速浏览这个文件,了解你的网站是做什么的、有哪些重要内容,然后按需去抓取具体页面。
llms-full.txt是重量级的全量内容文件,它把llms.txt中列出的所有关键页面的完整内容直接整合到一个文件里。AI不需要再去逐个抓取各个链接,一次请求就能获得全部核心信息。
ripgrep (rg) 核心定位依旧是一款高速、本地文件搜索工具,本身并不直接支持像搜索引擎那样搜索互联网上的网页。
一个经典的思路是将网页“本地化”。最直接的方法是使用 curl 命令下载网页源码,再通过管道 | 交给 ripgrep 搜索。这种方式适合对单个网页进行快速检查。
webgrep:一个现代化的工具,可以直接对任何URL进行搜索。它被描述为“网页版的ripgrep”,支持正则表达式和CSS选择器,能直接搜索HTML元素、文本、属性,甚至JavaScript代码。另外,webgrep 还提供一个 MCP服务器,可以集成到Claude Code等AI编程工具中,让AI使用该工具进行精确的网页搜索。
四、PageIndex 的选择 — Reasoning-based Retrieval 基于迭代推理的检索#
PageIndex 是一个将 TOC trees 目录树索引与迭代推理相结合的检索框架,尤其适用于长文档(报告、文件、手册、论文、教科书等),使 LLM 能够检索相关信息 ,而不仅仅是相似信息 ,从而为新一代智能文档理解系统铺平了道路。
它将文档表示为一个层级树目录索引,模拟了人类自然地浏览和提取长文档信息的方式。并将该索引直接放置在 LLM 的上下文窗口中 ,从而实现 ”dynamic, iterative reasoning process“,也就是:
1 动态的迭代推理过程#
Read the Table of Contents (ToC)
读取文档的树目录索引
Select a Section
根据动态变化的上下文(每一轮检索的信息、问题),推断出(下一个)最可能包含有用信息的页面、章节或段落
Extract Relevant Information
解析所选部分,提取相关信息
Is the Information Sufficient?
判断信息是否充足
- Yes → Proceed to Step 5
- No → Return to Step 1 and repeat the loop
Answer the Question
收集到足够的信息后,给出完整且论证充分的答案。

2 “Table of Contents” Index for LLMs 给大模型的目录索引#
“We introduce a JSON-based hierarchical structure to represent a Table of Contents (ToC) for unstructured documents.”
引入了一种基于 JSON 的层级结构来表示非结构化文档的目录 (ToC) 。该目录充当索引树 ,将内容组织成层级节点。每个节点代表一个逻辑部分(例如,章节、段落、页码),并且可以包含元数据、描述以及指向其子部分的链接。
This approach allows an LLM to:
- Traverse structured content recursively. 递归地遍历结构化内容。
- Retrieve targeted raw data by
node_id. 通过node_id检索目标原始数据。 - Associate contextual metadata (e.g., source type, topic, or semantic tags). 关联上下文元数据(例如,来源类型、主题或语义标签)。
PageIndex 树状索引示例(JSON 格式)
Node { node_id: string, // Unique node identifier name: string, // Human-readable label or title description: string, // Optional detailed explanation of the node metadata: object, // Arbitrary key-value pairs for context or attributes sub_nodes: [Node] // Array of child nodes (recursive structure)}node_id用作查找相应原始数据的引用键。sub_nodes字段允许递归嵌套,形成完整的目录树。metadata字段可以存储语义信息,例如文档类型、作者、时间戳或相关性评分。
Example PageIndex Tree
...{ "node_id": "0006", "title": "Financial Stability", "start_index": 21, "end_index": 22, "summary": "The Federal Reserve ...", "sub_nodes": [ { "node_id": "0007", "title": "Monitoring Financial Vulnerabilities", "start_index": 22, "end_index": 28, "summary": "The Federal Reserve's monitoring ..." }, { "node_id": "0008", "title": "Domestic and International Cooperation and Coordination", "start_index": 28, "end_index": 31, "summary": "In 2023, the Federal Reserve collaborated ..." } ]}...目录中的每个节点都直接链接到其对应的原始内容(例如,文本、图像、表格):
node_id → node_content (raw content, extracted text, images, etc.)这种映射使 LLM 能够根据需要选择和检索特定节点,从而实现精确且具有上下文感知的信息访问。
与存储外部静态嵌入索引的向量数据库不同, 基于 JSON 的目录索引驻留在 LLM 的动态推理上下文中。我们称之为上下文内索引 ——模型在推理过程中可以直接引用、导航和推理的结构。通过将索引集成到模型的上下文窗口中,LLM 可以动态地决定下一步的查找方向。
Overcoming the Limitations 克服局限性#
- 1 查询空间与知识空间不匹配 / 2 语义相似性 ≠ 真正相关性——PageIndex 不单独依赖”查询的语义“本身,而是运用 llm 动态推理理解查询意图、判断答案可能所在的章节,弥补了查询含义与相关文本之间的鸿沟,能够匹配真正相关的内容。
- 3 硬分块破坏语义完整性——基于推理的 RAG 算法并非随意分块,而是检索语义连贯的部分 (例如,整页、节或章节)。如果模型检测到某个部分不完整,它会迭代地获取相邻部分 (例如,下一页或子节点),直到上下文足够为止。这既能保持逻辑连续性,又能最大限度地减少信息错位。
- 4 无法利用历史对话——检索过程具有上下文感知能力 :模型会利用先前的对话历史来加深对当前问题的理解。例如,如果用户之前询问过“金融资产”,现在又问“负债呢?”,检索器就会知道应该在同一份报告的负债部分下进行探索。这使得跨多个对话回合的连贯、多步骤探索成为可能。
- 5 文档内引用难以处理——通过利用基于页面索引或目录的层级结构 ,基于推理的检索可以像人类读者一样浏览引用。当遇到类似 “参见附录 G” 这样的短语时,LLM 会导航到索引树中的相应部分并检索相关数据。这使得无需手动构建链接即可实现精确的交叉引用。
优点#
- Shorter, cleaner contexts 更简洁、更清晰的上下文。 代理仅检索所需信息,并确保答案牢牢基于源文档。
- Traceable and explainable reasoning for retrieval 检索过程具有可追溯性和可解释性。 检索由推理驱动,而非相似性匹配。每个结果都可以追溯到特定的节点、标题和页面;用于检索上下文的推理路径是透明且可审计的 ,从而清晰地展现了答案的来源和选择原因。
- Proven benchmark performance 经基准测试验证,性能卓越。 在广泛使用的金融质量保证基准测试工具 FinanceBench 上,基于 PageIndex 的检索方法达到了 98.7% 的准确率 ,优于基于向量的 RAG 管道以及市场上其他行业解决方案。
- Faster iteration cycles 更快的迭代周期。 更新标题、完善节点摘要或调整层级结构会立即生效,无需代价高昂的重新嵌入或索引重建。
- Human-readable debugging 便于理解的调试。 你不需要调试词嵌入或不透明的相似度评分。你需要检查文档结构、节点摘要和检索推理,以理解和纠正检索行为。
- Model portability 模型可移植性。 由于该索引是自描述且结构驱动的,因此您不会被锁定在特定的嵌入模型或向量数据库上。
上下文预算管理(通过树状搜索缓解)#
PageIndex is built to avoid context bloat by design: PageIndex 的设计初衷就是为了避免上下文臃肿 :
- The top-level tree index is compact (think a page or two). 顶级树索引很紧凑(大概只有一两页)。
- The agent can perform tree-based search, reasoning down the hierarchy and opening only the branches and leaf nodes that are relevant. 该代理可以执行基于树的搜索 ,向下推理层级结构,并仅打开相关的分支和叶节点。
- For very large documents, only the top k levels of the tree are loaded initially; deeper nodes are fetched on demand. 对于非常大的文档,最初只加载树的前 k 层 ;更深的节点按需获取。
简而言之,PageIndex 会预先加载结构而不是全文,从而保持上下文简洁,同时保留对完整文档的访问。
与 llms.txt 的区别#
- llms.txt is a flat directory of files, well suited for code repos. llms.txt 是一个扁平的文件目录 ,非常适合用作代码仓库。但需要高质量的描述;不太适合深度叙事结构
- PageIndex is a hierarchical structure of document context, ideal for understanding and navigating complex documents. PageIndex 是文档上下文的层次结构 ,非常适合理解和浏览复杂文档。
向量检索与 PageIndex 的使用场景#
Pick PageIndex when:
- long-form, structured documents 您的文档篇幅较长,结构严谨 ——财务报告、法律文件、技术手册、政策文件、医疗档案等等。
- need traceable, interpretable retrieval 你需要可追踪、可解释的检索 ——能够看到代理为什么打开了特定的部分或页面,以及为什么检索了某个段落,而不仅仅是检索了什么 。
- need context-relevant retrieval 你需要与上下文相关的检索 ——由对文档结构和上下文的推理驱动的检索,而不是对孤立片段的相似性匹配。
- prefer lightweight infrastructure 您更喜欢轻量级基础设施 ——没有向量存储,没有嵌入管道,维护开销也最小。
Pick vector search when:
- You’re working across many loosely related documents with weak or inconsistent structure. 您正在处理许多结构松散、关联性不强或前后不一致的文档。
- Queries are fuzzy or exploratory, and broad semantic recall across diverse content matters more than fine-grained precision, e.g., in recommendation or discovery systems. 查询是模糊的或探索性的,在推荐或发现系统中,跨各种内容的广泛语义回忆比精细的精确度更重要。
- prefer 成熟的工具生态系统